Bài 13: MST, Dijkstra, Topo Sort - Đồ Thị Nâng Cao¶
Tác giả: FPTOJ Team
Nội dung tham khảo từ: VNOI Wiki - Cây khung nhỏ nhất, Đường đi ngắn nhất, Sắp xếp Tô-pô
1. MST - Cây Khung Nhỏ Nhất¶
Bản chất vấn đề¶
Cho đồ thị vô hướng liên thông \(G = (V, E)\) với \(|V| = n\) đỉnh, \(|E| = m\) cạnh, mỗi cạnh có trọng số \(w(u,v)\). Tìm cây con \(T \subseteq E\) sao cho:
- \(T\) bao trùm tất cả \(n\) đỉnh (liên thông).
- Tổng trọng số \(\sum_{(u,v) \in T} w(u,v)\) là nhỏ nhất.
- \(T\) có đúng \(n - 1\) cạnh (không chu trình).
Đây là bài toán Cây khung nhỏ nhất (Minimum Spanning Tree - MST).
Tư duy cốt lõi¶
Có hai thuật toán kinh điển: Kruskal (cạnh-centric) và Prim (đỉnh-centric).
Kruskal - Tham lam trên cạnh:
Sắp xếp tất cả \(m\) cạnh theo trọng số tăng dần. Duyệt từng cạnh, nếu thêm cạnh đó không tạo chu trình thì chấp nhận. Dùng DSU (Disjoint Set Union) để kiểm tra chu trình trong \(O(\alpha(n))\).
graph LR
subgraph "Kruskal: Thêm cạnh theo trọng số"
A["Sắp xếp m cạnh tăng dần"] --> B["Duyệt cạnh e = (u,v,w)"]
B --> C{"find(u) ≠ find(v)?"}
C -->|"Có"| D["unite(u,v), thêm e vào MST"]
C -->|"Không"| E["Bỏ qua (tạo chu trình)"]
D --> F{"Đã có n-1 cạnh?"}
E --> B
F -->|"Chưa"| B
F -->|"Rồi"| G["Hoàn thành MST"]
endPrim - Tham lam trên đỉnh:
Bắt đầu từ đỉnh tùy ý. Mỗi bước, chọn cạnh có trọng số nhỏ nhất nối một đỉnh đã thăm với một đỉnh chưa thăm. Dùng min-heap để trích xuất cạnh nhỏ nhất nhanh.
graph LR
subgraph "Prim: Mở rộng từ đỉnh đã thăm"
A["Chọn đỉnh nguồn s"] --> B["Đưa các cạnh kề s vào min-heap"]
B --> C["Pop cạnh nhỏ nhất (w, v)"]
C --> D{"v đã thăm?"}
D -->|"Rồi"| C
D -->|"Chưa"| E["Thêm v vào MST, cập nhật tổng trọng số"]
E --> F["Đưa các cạnh kề v vào heap"]
F --> C
endPhân tích tính đúng đắn¶
Cut Property (Tính chất cắt): Với mọi tập \(S \subset V\) (\(S \neq \emptyset, S \neq V\)), cạnh có trọng số nhỏ nhất giữa \(S\) và \(V \setminus S\) nhất định thuộc MST.
Kruskal đúng vì: Khi xét cạnh \((u,v)\) nhỏ nhất chưa xét, nếu \(u\) và \(v\) thuộc hai thành phần liên thông khác nhau (tạo một "cắt"), thì \((u,v)\) là cạnh nhỏ nhất qua cắt đó → thuộc MST theo Cut Property.
Prim đúng vì: Tại mỗi bước, tập đỉnh đã thăm tạo một cắt. Cạnh nhỏ nhất nối đỉnh đã thăm với đỉnh chưa thăm chính là cạnh nhỏ nhất qua cắt đó → thuộc MST.
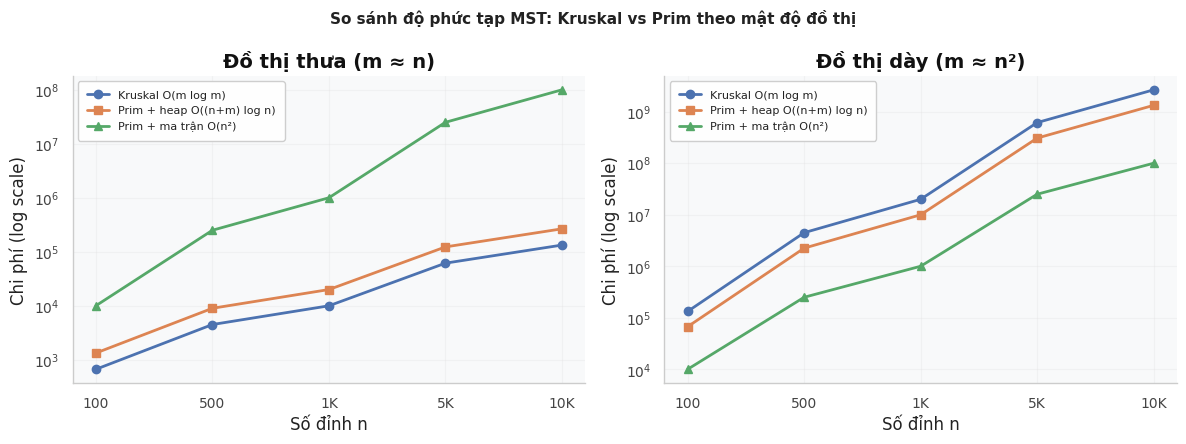
Đánh giá độ phức tạp¶
| Thuật toán | Độ phức tạp | Ghi chú |
|---|---|---|
| Kruskal | \(O(m \log m)\) | Chi phối bởi bước sắp xếp cạnh |
| Prim (heap) | \(O((n + m) \log n)\) | Mỗi cạnh push/pop heap tối đa 1 lần |
| Prim (ma trận) | \(O(n^2)\) | Tốt hơn khi \(m\) lớn (đồ thị dày) |
Kruskal phù hợp khi đồ thị thưa (\(m \approx n\)). Prim với heap phù hợp khi đồ thị trung bình. Prim với ma trận kề phù hợp khi đồ thị rất dày (\(m \approx n^2\)).
Thử tương tác
2. Dijkstra - Đường Đi Ngắn Nhất¶
Bản chất vấn đề¶
Cho đồ thị có hướng (hoặc vô hướng) \(G = (V, E)\) với trọng số không âm \(w(u,v) \geq 0\), đỉnh nguồn \(s\). Tìm đường đi từ \(s\) đến mọi đỉnh \(v\) sao cho tổng trọng số \(d(s,v) = \sum w\) là nhỏ nhất.
Đây là bài toán Đường đi ngắn nhất nguồn đơn (Single-Source Shortest Path - SSSP).
Tư duy cốt lõi¶
Dijkstra là thuật toán tham lam: luôn mở rộng từ đỉnh có khoảng cách tạm thời nhỏ nhất.
Bất biến quan trọng: Khi một đỉnh \(u\) được lấy ra từ priority queue, \(dist[u]\) đã là giá trị cuối cùng — không thể cải thiện thêm.
Điều kiện: Trọng số phải không âm. Nếu có cạnh trọng số âm, dùng Bellman-Ford thay thế.
graph LR
subgraph "Dijkstra: Mở rộng đỉnh gần nhất"
A["dist[s] = 0, push (0,s) vào PQ"] --> B["Pop đỉnh u có dist[u] nhỏ nhất"]
B --> C{"d > dist[u]?"}
C -->|"Có"| D["Bỏ qua (đã xử lý rồi)"]
C -->|"Không"| E["Duyệt kề v của u"]
E --> F{"dist[u] + w < dist[v]?"}
F -->|"Có"| G["Cập nhật dist[v], push vào PQ"]
F -->|"Không"| E
G --> E
D --> B
endMinh họa chạy chi tiết¶
Xét đồ thị sau với đỉnh nguồn \(s = 1\):
graph LR
1 --"w=1"--> 2
1 --"w=4"--> 3
2 --"w=2"--> 4
3 --"w=1"--> 4Bảng trace từng bước (PQ = priority queue, lưu (dist, đỉnh)):
| Bước | Pop | Duyệt cạnh | Cập nhật \(dist\) | PQ sau bước |
|---|---|---|---|---|
| Khởi tạo | - | - | \(dist = [\infty, 0, \infty, \infty]\) | \([(0,1)]\) |
| 1 | \((0, 1)\) | \((1,2): dist[1]+1=1\), \((1,3): dist[1]+4=4\) | \(dist[2]=1, dist[3]=4\) | \([(1,2), (4,3)]\) |
| 2 | \((1, 2)\) | \((2,4): dist[2]+2=3\) | \(dist[4]=3\) | \([(3,4), (4,3)]\) |
| 3 | \((3, 4)\) | Không có kề | - | \([(4,3)]\) |
| 4 | \((4, 3)\) | \((3,4): dist[3]+1=5 > dist[4]=3\) | Không cập nhật | \([]\) |
Kết quả: \(dist = [\infty, 0, 1, 4, 3]\). Đường ngắn nhất \(1 \to 4\): \(1 \to 2 \to 4\), độ dài \(= 3\).
Lưu ý: Tại bước 4, đỉnh 3 cố gắng cập nhật \(dist[4]\) nhưng bị bỏ qua vì \(5 > 3\). Đây là lý do Dijkstra chỉ hoạt động đúng với trọng số không âm.
Phân tích tính đúng đắn¶
Lemma: Khi đỉnh \(u\) được pop ra khỏi PQ với \(d = dist[u]\), thì \(dist[u]\) đã là khoảng cách ngắn nhất từ \(s\) đến \(u\).
Chứng minh (phản chứng): Giả sử \(dist[u]\) chưa tối ưu, tức tồn tại đường đi ngắn hơn qua đỉnh \(x\) chưa xử lý. Khi đó \(dist[x] < dist[u]\) (vì đường đi qua \(x\) ngắn hơn). Nhưng \(x\) chưa xử lý nghĩa là \(x\) vẫn trong PQ với ưu tiên \(\leq dist[x] < dist[u]\), nên \(x\) phải được pop trước \(u\). Mâu thuẫn.
Suy ra thuật toán luôn pop đỉnh có khoảng cách ngắn nhất trước → đảm bảo tính đúng đắn.
Đánh giá độ phức tạp¶
| Thành phần | Độ phức tạp |
|---|---|
| Mỗi đỉnh | Pop từ heap: \(O(\log n)\) |
| Mỗi cạnh | Push vào heap tối đa 1 lần: \(O(\log n)\) |
| Tổng | \(O((n + m) \log n)\) |
Với Fibonacci heap, độ phức tạp cải thiện còn \(O(n \log n + m)\), nhưng ít dùng trong thi đấu.
Dijkstra chỉ cho trọng số không âm
Nếu đồ thị có cạnh trọng số âm, dùng Bellman-Ford (\(O(nm)\)) hoặc SPFA thay thế. Xem Bài 23: Floyd-Warshall & Bellman-Ford.
3. Sắp Xếp Tô-pô (Topological Sort)¶
Bản chất vấn đề¶
Cho đồ thị có hướng không chu trình (DAG) \(G = (V, E)\) với \(|V| = n\) đỉnh, \(|E| = m\) cạnh. Tìm một hoán vị \(\sigma\) của các đỉnh sao cho với mọi cạnh \((u, v) \in E\), ta có \(\sigma(u) < \sigma(v)\) — tức mọi cạnh đều hướng từ trái sang phải.
Đây là bài toán Sắp xếp tô-pô (Topological Sort). Nếu đồ thị có chu trình, không tồn tại thứ tự tô-pô.
Tư duy cốt lõi¶
Phổ biến nhất là thuật toán Kahn dựa trên bậc vào (in-degree):
- Tính bậc vào \(in[v]\) cho mỗi đỉnh \(v\).
- Đỉnh nào có \(in[v] = 0\) (không bị phụ thuộc) được đưa vào hàng đợi.
- Lấy đỉnh \(u\) ra, "loại bỏ" \(u\) bằng cách giảm \(in[v]\) cho mọi đỉnh \(v\) kề \(u\).
- Nếu \(in[v]\) giảm về \(0\), đưa \(v\) vào hàng đợi.
- Lặp cho đến khi hàng đợi rỗng.
graph TD
subgraph "Kahn: Xử lý đỉnh bậc vào = 0"
A["Tính in-degree cho mọi đỉnh"] --> B["Đưa đỉnh có in=0 vào queue"]
B --> C["Pop đỉnh u, thêm vào kết quả"]
C --> D["Giảm in[v] cho mỗi kề v của u"]
D --> E{"in[v] == 0?"}
E -->|"Có"| F["Đưa v vào queue"]
E -->|"Không"| D
F --> C
endMinh họa chạy chi tiết¶
Xét DAG sau:
graph LR
1 --> 2
1 --> 3
2 --> 4
3 --> 4
4 --> 5| Bước | Queue | Pop | Kết quả | Cập nhật \(in\) |
|---|---|---|---|---|
| Khởi tạo | \([1]\) | - | \([]\) | \(in = [0, 1, 1, 2, 1]\) |
| 1 | \([2, 3]\) | \(1\) | \([1]\) | \(in[2] \to 0, in[3] \to 0\) |
| 2 | \([3]\) | \(2\) | \([1, 2]\) | \(in[4] \to 1\) |
| 3 | \([4]\) | \(3\) | \([1, 2, 3]\) | \(in[4] \to 0\) |
| 4 | \([5]\) | \(4\) | \([1, 2, 3, 4]\) | \(in[5] \to 0\) |
| 5 | \([]\) | \(5\) | \([1, 2, 3, 4, 5]\) | - |
Kết quả: \([1, 2, 3, 4, 5]\) — mọi cạnh đều hướng từ trái sang phải.
Phân tích tính đúng đắn¶
Tính đúng đắn của Kahn:
- Mỗi đỉnh được đưa vào queue đúng một lần khi \(in[v] = 0\), tức tất cả đỉnh "tiên quyết" của \(v\) đã được xử lý.
- Nếu kết quả chứa đủ \(n\) đỉnh: mọi đỉnh đều được xử lý, và mọi cạnh \((u,v)\) đều hướng từ trái sang phải vì \(u\) luôn được xử lý trước \(v\) (do \(in[v]\) chỉ giảm về \(0\) sau khi \(u\) đã pop).
- Nếu kết quả có \(< n\) đỉnh: tồn tại chu trình. Khi đó, các đỉnh trong chu trình có \(in > 0\) vĩnh viễn vì chúng phụ thuộc lẫn nhau.
Đánh giá độ phức tạp¶
| Thành phần | Độ phức tạp |
|---|---|
| Tính \(in\)-degree | \(O(n + m)\) |
| Duyệt queue | \(O(n + m)\) (mỗi đỉnh/enqueue đúng 1 lần) |
| Tổng | \(O(n + m)\) |
Sắp xếp tô-pô có độ phức tạp tuyến tính — rất hiệu quả.
4. Tổng hợp & Bẫy hay gặp¶
Bảng so sánh¶
| Thuật toán | Khi nào dùng | Độ phức tạp |
|---|---|---|
| Kruskal | MST, cạnh ít (đồ thị thưa) | \(O(m \log m)\) |
| Prim | MST, cạnh nhiều (đồ thị dày) | \(O((n+m) \log n)\) |
| Dijkstra | Đường đi ngắn nhất, trọng số \(\geq 0\) | \(O((n+m) \log n)\) |
| Topo Sort | Sắp xếp thứ tự ưu tiên trên DAG | \(O(n + m)\) |
Bẫy hay gặp¶
Bẫy 1: Dijkstra với trọng số âm
Dijkstra không hoạt động đúng khi có trọng số âm. Khi đỉnh \(u\) được pop, \(dist[u]\) được coi là tối ưu — nhưng trọng số âm có thể tạo đường đi ngắn hơn qua đỉnh chưa xử lý. Dùng Bellman-Ford thay thế.
Bẫy 2: Topo Sort trên đồ thị có chu trình
Nếu kết quả có \(< n\) đỉnh, đồ thị có chu trình. Quên kiểm tra điều kiện này sẽ dẫn đến kết quả sai mà không biết.
Bẫy 3: MST trên đồ thị không liên thông
Nếu số cạnh được chọn \(< n - 1\), đồ thị không liên thông và không tồn tại MST. Luôn kiểm tra edges_used == n - 1 (Kruskal) hoặc count == n (Prim).
Bẫy 4: Quên visited trong Prim
Nếu không kiểm tra visited[u] trước khi xử lý, đỉnh sẽ bị xử lý nhiều lần do cùng một đỉnh có thể nằm nhiều lần trong heap với trọng số khác nhau.
Bẫy 5: Dijkstra — quên bỏ qua đỉnh cũ trong heap
Điều kiện if (d > dist[u]) continue là bắt buộc. Heap có thể chứa nhiều bản ghi cho cùng một đỉnh; chỉ bản ghi có \(dist\) nhỏ nhất là hợp lệ.
Bài tập luyện tập¶
| Bài | Nền tảng | Độ khó | Chủ đề |
|---|---|---|---|
| CSES - Road Reparation | CSES | ⭐⭐ | MST |
| CSES - Road Construction | CSES | ⭐⭐ | DSU + MST |
| CSES - Shortest Routes I | CSES | ⭐⭐ | Dijkstra |
| CSES - Shortest Routes II | CSES | ⭐⭐ | Floyd-Warshall |
| CSES - Course Schedule | CSES | ⭐⭐ | Topo Sort |
| CSES - Longest Flight Route | CSES | ⭐⭐⭐ | Topo + DP |
| VNOJ - QBMST | VNOJ | ⭐⭐ | MST cơ bản |
| VNOJ - DIJKSTRA | VNOJ | ⭐⭐ | Dijkstra |
| VNOJ - TOPOSORT | VNOJ | ⭐⭐ | Topo sort |
Bài tập thực hành trên FPTOJ¶
Dưới đây là danh sách 30 bài tập thực hành được đồng bộ trên hệ thống FPTOJ:
| Mã bài | Tên bài tập | Độ khó | Chuyên đề | Bản chất bài tập | Lời giải chi tiết |
|---|---|---|---|---|---|
mst-road |
Tuyến đường liên tỉnh | ⭐⭐ | MST | Kruskal/Prim cơ bản | Xem hướng dẫn |
mst-cable |
Lắp đặt cáp mạng | ⭐⭐ | MST | Prim trên lưới ~2D~ tọa độ thực | Xem hướng dẫn |
mst-cliques |
Xây dựng cầu cảng | ⭐⭐ | MST | Khởi tạo cạnh trọng số ~0~ | Xem hướng dẫn |
mst-reduce |
Tối ưu hóa mạng lưới | ⭐⭐ | MST | Xóa cạnh thừa tối ưu | Xem hướng dẫn |
mst-connect |
Kết nối nguồn điện | ⭐⭐⭐ | MST | MST với nhiều nguồn phát sẵn | Xem hướng dẫn |
mst-forest |
Phân cụm động vật | ⭐⭐⭐ | MST | Chia thành ~K~ thành phần liên thông | Xem hướng dẫn |
mst-maxedge |
Hành trình an toàn | ⭐⭐⭐ | MST | Minimax edge trên đường đi | Xem hướng dẫn |
mst-k-comp |
Kết nối các khu vực | ⭐⭐⭐ | MST | Gom cạnh có sẵn và chọn thêm cạnh | Xem hướng dẫn |
topo-schedule |
Lập lịch công việc | ⭐⭐ | Topo Sort | Kahn in-degree cơ bản | Xem hướng dẫn |
topo-build |
Xây dựng căn nhà | ⭐⭐ | Topo Sort | Sắp xếp topo phát hiện chu trình | Xem hướng dẫn |
topo-course |
Chọn môn đăng ký học | ⭐⭐ | Topo Sort | Sắp xếp thứ tự môn học tiên quyết | Xem hướng dẫn |
topo-recipe |
Pha chế độc dược | ⭐⭐ | Topo Sort | Chuỗi chuẩn bị nguyên liệu | Xem hướng dẫn |
topo-cycle |
Phát hiện điểm nghẽn | ⭐⭐ | Topo Sort | Kiểm tra tính khả thi của DAG | Xem hướng dẫn |
topo-lex |
Lập lịch ưu tiên từ điển | ⭐⭐⭐ | Topo Sort | Kahn dùng min-heap tìm thứ tự từ điển | Xem hướng dẫn |
topo-critical |
Đường găng dự án | ⭐⭐⭐ | Topo Sort | DP đường đi dài nhất trên DAG | Xem hướng dẫn |
topo-alien |
Mật thư cổ đại | ⭐⭐⭐⭐ | Topo Sort | Giải mã thứ tự chữ cái trong từ điển | Xem hướng dẫn |
dij-shortest |
Đường đi ngắn nhất | ⭐⭐ | Dijkstra | Dijkstra cơ bản với priority queue | Xem hướng dẫn |
dij-multi |
Giao hàng từ nhiều kho | ⭐⭐ | Dijkstra | Multi-source Dijkstra | Xem hướng dẫn |
dij-grid |
Mê cung trọng số | ⭐⭐ | Dijkstra | Dijkstra trên lưới ~2D~ | Xem hướng dẫn |
dij-edges |
Đường đi ưu tiên ít cạnh | ⭐⭐ | Dijkstra | So sánh tối ưu kép | Xem hướng dẫn |
dij-hwy |
Xa lộ và quốc lộ | ⭐⭐ | Dijkstra | Trọng số thời gian thực ~L / V~ | Xem hướng dẫn |
dij-minimax |
Độ dốc tối thiểu | ⭐⭐⭐ | Dijkstra | Tìm minimax path | Xem hướng dẫn |
dij-weight |
Giới hạn tải trọng | ⭐⭐⭐ | Dijkstra | Lọc cạnh theo điều kiện tải trọng xe | Xem hướng dẫn |
dij-matrix |
Tìm đường đồ thị đầy | ⭐⭐⭐ | Dijkstra | Dijkstra quét mảng ~O(N^2)~ cho đồ thị dày | Xem hướng dẫn |
dij-flight |
Đặt vé máy bay | ⭐⭐⭐ | Dijkstra | Đồ thị trạng thái nhân đôi tầng | Xem hướng dẫn |
dij-repair |
Sửa chữa đường bộ | ⭐⭐⭐ | Dijkstra | Trạng thái ~dist[u][repairs]~ giới hạn hỏng | Xem hướng dẫn |
dij-rev |
Đi ngược chiều tối thiểu | ⭐⭐⭐ | Dijkstra | Đi ngược chiều tối đa ~K~ cạnh | Xem hướng dẫn |
dij-k-path |
Hành trình ngắn thứ K | ⭐⭐⭐⭐ | Dijkstra | Dijkstra pop-count tìm k-th path | Xem hướng dẫn |
dij-charge |
Trạm sạc xe điện | ⭐⭐⭐⭐ | Dijkstra | Dijkstra 2D trạng thái pin giới hạn ~C~ | Xem hướng dẫn |
dij-fuel |
Bình xăng giới hạn | ⭐⭐⭐⭐ | Dijkstra | Trạng thái bình xăng ~dist[u][fuel]~ | Xem hướng dẫn |
Bài viết liên quan¶
Tài liệu tham khảo¶
- VNOI Wiki - Cây khung nhỏ nhất
- VNOI Wiki - Đường đi ngắn nhất
- VNOI Wiki - Sắp xếp Tô-pô
- CP-Algorithms - Prim's Algorithm
- CP-Algorithms - Kruskal's Algorithm
- CP-Algorithms - Topological Sort
Bài tiếp theo: Hash xâu & Z-algorithm →