Bài 1: Độ Phức Tạp Thời Gian¶
Tác giả: FPTOJ Team
Nội dung tham khảo từ: VNOI Wiki - Độ phức tạp thời gian, Topcoder - Computational Complexity
Bản chất vấn đề¶
Bài toán: Ai là người chạy nhanh nhất?¶
Giả sử bạn có 2 người bạn - An và Bình - cùng nhận nhiệm vụ tìm một cuốn sách trong thư viện có \(N\) kệ sách.
-
An lười biếng: cô ấy đi từ kệ đầu tiên đến kệ cuối cùng, lần lượt kiểm tra từng kệ một. Nếu \(N = 10^6\) kệ, cô ấy phải kiểm tra cả \(10^6\) kệ.
-
Bình thông minh hơn: vì sách đã được xếp theo thứ tự ABC, Bình chia đôi giá sách, loại bỏ một nửa mỗi lần. Với \(N = 10^6\) kệ, Bình chỉ cần kiểm tra khoảng 20 lần là xong.
Cùng một bài toán, nhưng thuật toán khác nhau dẫn đến thời gian chạy khác nhau cực kỳ lớn.
Câu hỏi đặt ra: Làm sao để biết thuật toán nào nhanh, thuật toán nào chậm trước khi chạy thử? Đó chính là lý do ta cần học về Độ phức tạp thời gian.
Tại sao cần phân tích độ phức tạp?¶
Trong lập trình thi đấu, thời gian giới hạn thường là 1 giây, tương đương khoảng \(10^8\) phép tính. Nếu thuật toán của bạn chạy quá lâu, bạn sẽ bị TLE (Time Limit Exceeded) dù kết quả đúng.
Phân tích độ phức tạp giúp bạn:
- Đánh giá trước thuật toán có kịp chạy trong giới hạn thời gian hay không
- So sánh nhiều thuật toán giải cùng bài toán
- Tối ưu code khi cần thiết
Tư duy cốt lõi¶
Toán học bổ trợ: Logarit¶
Logarit cơ số 2 của \(N\) (viết là \(\log_2 N\)) là số lần bạn phải nhân 2 với chính nó để ra \(N\).
Ví dụ:
- \(\log_2(8) = 3\), vì \(2 \times 2 \times 2 = 8\) (nhân 3 lần)
- \(\log_2(16) = 4\), vì \(2 \times 2 \times 2 \times 2 = 16\) (nhân 4 lần)
- \(\log_2(10^6) \approx 20\)
Vì sao quan trọng? Khi một thuật toán "chia đôi" vấn đề mỗi bước (như Bình tìm sách), số bước cần thiết chính là \(\log_2 N\).
Bảng tra cứu nhanh:
| \(N\) | \(\log_2 N\) (xấp xỉ) |
|---|---|
| \(10^3\) | 10 |
| \(10^6\) | 20 |
| \(10^9\) | 30 |
Lưu ý: Trong lập trình thi đấu, ta viết gọn là \(\log N\) mà không cần ghi cơ số. Vì \(\log_2 N\), \(\log_{10} N\), \(\ln N\) chỉ khác nhau một hằng số, mà hằng số thì ta bỏ qua.
O-lớn (Big-O) - Chiếc "máy đo" tốc độ thuật toán¶
Thay vì đếm chính xác "thuật toán chạy 1.532.789 bước", ta chỉ cần biết nó tăng nhanh như thế nào khi dữ liệu đầu vào tăng.
O-lớn là cách viết tắt để nói: "Khi \(N\) đủ lớn, thuật toán này chạy không quá \(c \times f(N)\) bước".
Ví dụ:
- \(f(n) = 2n + 10\) là \(O(n)\), vì khi \(n\) đủ lớn, 10 không đáng kể, \(2n\) cũng chỉ là "\(n\) với hệ số nhỏ"
- \(f(n) = 3n^2 + 5n + 100\) là \(O(n^2)\), vì khi \(n\) đủ lớn, \(3n^2\) "nuốt chửng" mọi thứ còn lại
Nguyên tắc đơn giản: Chỉ giữ số mũ cao nhất, bỏ hệ số và số hạng nhỏ hơn.
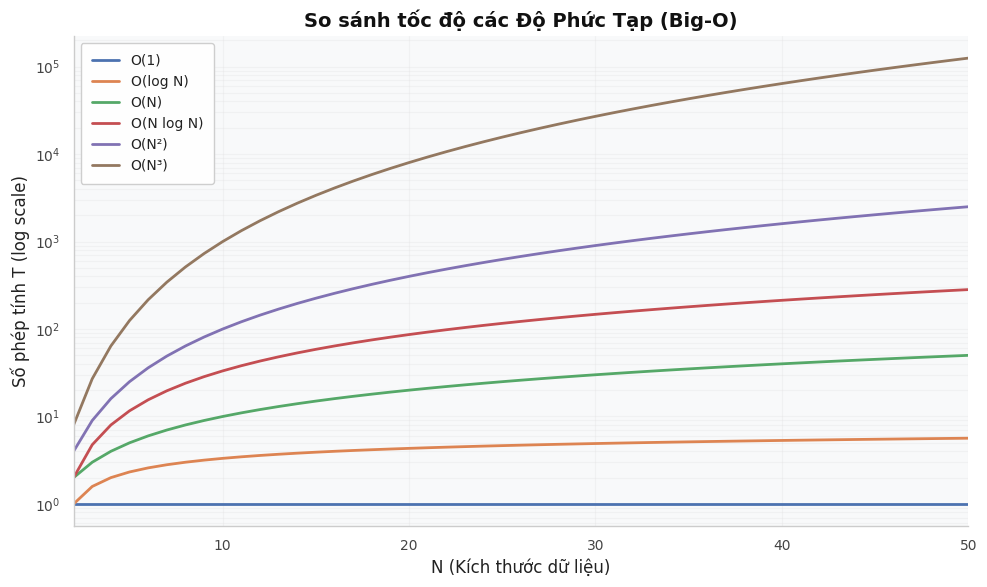
Bảng "tốc độ" các độ phức tạp thường gặp¶
Hãy tưởng tượng máy tính chạy khoảng \(10^8\) phép tính/giây. Bảng dưới cho biết \(N\) lớn nhất để thuật toán chạy xong trong 1 giây:
| \(O(?)\) | Tên gọi | \(N\) tối đa | Ví dụ thực tế |
|---|---|---|---|
| \(O(1)\) | Hằng số | Tùy ý | Lấy phần tử đầu mảng |
| \(O(\log N)\) | Logarit | \(10^{18}\) | Tìm kiếm nhị phân |
| \(O(N)\) | Tuyến tính | \(10^8\) | Duyệt mảng |
| \(O(N \log N)\) | "\(N \log N\)" | \(10^6\) | Merge Sort, Quick Sort |
| \(O(N^2)\) | Bậc 2 | \(10^4\) | 2 vòng lặp lồng nhau |
| \(O(N^3)\) | Bậc 3 | \(500\) | 3 vòng lặp lồng nhau |
| \(O(2^N)\) | Mũ | \(20\) | Quay lui thử mọi trường hợp |
| \(O(N!)\) | Giai thừa | \(11\) | Sinh tất cả hoán vị |
Cách tính O-lớn cho code - 3 quy tắc vàng¶
Quy tắc 1: Vòng lặp for i = 1 to N là \(O(N)\).
Quy tắc 2: Hai vòng lặp liên tiếp (nối đuôi nhau) thì cộng độ phức tạp.
Quy tắc 3: Hai vòng lặp lồng nhau thì nhân độ phức tạp.
Ví dụ phân tích code¶
Ví dụ 1: Hai vòng lặp nối tiếp
Ví dụ 2: Hai vòng lặp lồng nhau
Ví dụ 3: Vòng trong chạy ít hơn
Kĩ thuật Hai con trỏ - Kẻ lừa đảo!¶
Xem đoạn code này:
Thoạt nhìn: vòng lặp lồng nhau, vậy là \(O(n^2)\)?
Sai! Hãy đếm tổng số lần j++ chạy trong TOÀN BỘ chương trình: \(j\) chỉ tăng từ 0 đến \(n\), mỗi giá trị tối đa 1 lần. Vậy tổng số lần tăng là \(O(n)\).
Tổng cộng: \(i\) chạy \(n\) lần + \(j\) chạy \(n\) lần = \(O(n) + O(n) = O(n)\).
Bài học: Không phải cứ thấy vòng lặp lồng là \(O(n^2)\)! Phải xem xét kĩ biến bên trong chạy bao nhiêu lần tổng cộng.
Độ phức tạp bộ nhớ (Space Complexity)¶
Bên cạnh thời gian, máy tính còn giới hạn về bộ nhớ (thường là 256MB hoặc 512MB).
Nguyên tắc ước lượng:
- Một biến
inttốn 4 bytes - Mảng
int a[10^6]tốn ~4MB - Mảng
int a[10^4][10^4](\(10^8\) phần tử) tốn ~400MB, dễ bị quá giới hạn (MLE)
| Độ phức tạp | Giải thích | Ví dụ |
|---|---|---|
| \(O(1)\) | Dùng vài biến đơn lẻ | Tính tổng 2 số |
| \(O(N)\) | Dùng mảng 1 chiều kích thước \(N\) | Lưu danh sách học sinh |
| \(O(N^2)\) | Dùng mảng 2 chiều \(N \times N\) | Ma trận kề, bảng DP 2D |
Mẹo: Trong lập trình thi đấu, ưu tiên tiết kiệm bộ nhớ nếu có thể (ví dụ: dùng DP 1D thay vì 2D).
Phân tích tính đúng đắn¶
Tại sao bỏ hằng số và số hạng nhỏ hơn?¶
Giả sử bạn có hai thuật toán:
- Thuật toán A: \(f(n) = 2n + 10\)
- Thuật toán B: \(g(n) = 3n^2 + 5n + 100\)
Khi \(n = 10\):
- \(f(10) = 2 \times 10 + 10 = 30\)
- \(g(10) = 3 \times 100 + 5 \times 10 + 100 = 450\)
Khi \(n = 100\):
- \(f(100) = 2 \times 100 + 10 = 210\)
- \(g(100) = 3 \times 10000 + 5 \times 100 + 100 = 30600\)
Khi \(n = 1000\):
- \(f(1000) = 2 \times 1000 + 10 = 2010\)
- \(g(1000) = 3 \times 1000000 + 5 \times 1000 + 100 = 3005100\)
Nhận xét: Khi \(n\) càng lớn, số hạng có bậc cao nhất càng "nuốt chửng" các số hạng còn lại. Đó là lý do ta chỉ quan tâm đến bậc cao nhất.
Tại sao kĩ thuật hai con trỏ cho \(O(n)\)?¶
Trong đoạn code hai con trỏ, biến \(j\) chỉ tăng từ 0 đến \(n\). Mỗi lần tăng, giá trị của \(j\) không bao giờ giảm. Vậy tổng số lần tăng của \(j\) trong toàn bộ chương trình là tối đa \(n\).
Biến \(i\) cũng chạy từ 0 đến \(n\), tổng số lần lặp là \(n\).
Tổng số phép tính = (số lần lặp của \(i\)) + (tổng số lần tăng của \(j\)) = \(n + n = 2n = O(n)\).
Đây là kĩ thuật quan trọng trong lập trình thi đấu: không đếm số lần lặp của vòng trong trong mỗi lần lặp của vòng ngoài, mà đếm tổng cộng số lần biến bên trong thay đổi giá trị.
Tại sao \(\sum_{i=1}^{n} \frac{n}{i} = O(n \log n)\)?¶
Xét đoạn code:
Vòng trong chạy với bước nhảy \(i\), nên số lần chạy là \(\lfloor \frac{n}{i} \rfloor\).
Tổng số lần chạy của vòng trong:
Tổng \(\sum_{i=1}^{n} \frac{1}{i}\) là chuỗi điều hòa, có giá trị xấp xỉ \(\ln n + \gamma\) (với \(\gamma \approx 0.577\) là hằng số Euler-Mascheroni).
Vậy tổng số lần chạy là \(O(n \log n)\), không phải \(O(n^2)\).
Đánh giá độ phức tạp¶
Đo thời gian chạy thực tế¶
Đoạn code dưới đây so sánh thời gian chạy thực tế của các độ phức tạp khác nhau:
Tìm kiếm nhị phân - \(O(\log N)\)¶
Tìm kiếm nhị phân là thuật toán kinh điển có độ phức tạp \(O(\log N)\):
Mỗi bước, khoảng tìm kiếm giảm một nửa. Số bước tối đa là \(\log_2 N\).
Bảng tổng hợp độ phức tạp¶
| Độ phức tạp | Tên gọi | \(N\) tối đa trong 1s | Ví dụ thuật toán |
|---|---|---|---|
| \(O(1)\) | Hằng số | Tùy ý | Truy cập mảng |
| \(O(\log N)\) | Logarit | \(10^{18}\) | Tìm kiếm nhị phân |
| \(O(N)\) | Tuyến tính | \(10^8\) | Duyệt mảng |
| \(O(N \log N)\) | Linearithmic | \(10^6\) | Merge Sort |
| \(O(N^2)\) | Bậc 2 | \(10^4\) | Bubble Sort |
| \(O(N^3)\) | Bậc 3 | \(500\) | Floyd-Warshall |
| \(O(2^N)\) | Mũ | \(20\) | Quay lui tổ hợp |
| \(O(N!)\) | Giai thừa | \(11\) | Sinh hoán vị |
Lưu ý / Cạm bẫy hay gặp¶
Bẫy 1: \(O(N^2)\) với \(N = 10^5\) sẽ bị TLE¶
Nếu đề cho \(N \leq 10^5\), thì \(O(N^2) = 10^{10}\) phép tính, quá 1 giây. Bạn cần tìm thuật toán \(O(N \log N)\) hoặc \(O(N)\).
Mẹo: Nhìn \(N\) trong đề bài, tra bảng ở trên để biết thuật toán nào "đọ" được.
Bẫy 2: Hằng số ẩn - Kẻ thù giấu mặt¶
Hai thuật toán cùng \(O(N)\) không có nghĩa chạy nhanh như nhau.
Cả hai đều \(O(N)\), nhưng cách 2 chậm gấp 1000 lần.
Bẫy 3: Tràn số khi tính mid¶
Bẫy 4: \(O(1)\) không có nghĩa là "chạy nhanh"¶
\(O(1)\) chỉ nghĩa là không phụ thuộc vào \(N\). Nó có thể là 1 phép tính, nhưng cũng có thể là \(10^9\) phép tính (hằng số rất lớn).
Ví dụ: Một thuật toán quay lui chơi cờ vua là \(O(1)\) vì bàn cờ có giới hạn cố định (\(8 \times 8\)). Nhưng "hằng số" đó lớn đến mức vũ trụ cũng không đủ thời gian.
Bẫy 5: Đừng quên \(\log N\) trong phân tích¶
Khi gặp code kiểu này:
Vòng trong chạy \(\frac{n}{1} + \frac{n}{2} + \frac{n}{3} + \ldots + \frac{n}{n} = n \times \left(1 + \frac{1}{2} + \frac{1}{3} + \ldots + \frac{1}{n}\right) \approx n \times \log N\).
Độ phức tạp là \(O(N \log N)\), không phải \(O(N^2)\).
Chúc mừng! Bạn đã nắm được nền tảng quan trọng nhất trong lập trình thi đấu. Từ giờ, mỗi khi viết code, hãy tự hỏi: "Thuật toán của mình có độ phức tạp là bao nhiêu? Nó có kịp chạy trong thời gian giới hạn không?"
Bài tập luyện tập¶
Hãy thử sức với các bài tập phân tích và tối ưu độ phức tạp thuật toán sau đây trên hệ thống tự host:
| Bài | Nền tảng | Độ khó | Mục đích |
|---|---|---|---|
| An và chiếc máy tính | FPTOJ | ⭐ | Tối ưu độ phức tạp tính tổng dãy số từ ~O(N)~ về ~O(1)~ |
| Đếm cặp số của An | FPTOJ | ⭐⭐ | Tối ưu từ thuật toán duyệt cặp ~O(N^2)~ về đếm tần suất ~O(N)~ |
| Trò chơi lũy thừa | FPTOJ | ⭐⭐⭐ | Sử dụng Lũy thừa nhị phân để tối ưu phép tính ~A^B \pmod M~ về ~O(\log B)~ |
| Dãy con của Việt | FPTOJ | ⭐⭐⭐ | Tìm đoạn con liên tiếp có tổng lớn nhất bằng thuật toán Kadane ~O(N)~ thay vì ~O(N^2)~ |
| Số lượng ước số | FPTOJ | ⭐⭐⭐⭐ | Rút gọn thuật toán đếm ước số tự nhiên từ ~O(\sqrt{N})~ về ~O(1)~ bằng tính chất số chính phương |
Bài viết liên quan¶
Tài liệu tham khảo¶
- VNOI Wiki - Độ phức tạp thời gian
- Topcoder - Computational Complexity Section 1
- Topcoder - Computational Complexity Section 2
- GeeksforGeeks - Time Complexity Analysis
- YouTube - Big O Notation (freeCodeCamp)
Bài tiếp theo: Thuật toán sắp xếp