Bài 46: Heavy-Light Decomposition - Phân rã cây!¶
Tác giả: FPTOJ Team
Nội dung tham khảo từ: VNOI Wiki, CP-Algorithms
Bạn sẽ học được gì?¶
- Heavy/Light edges là gì và tại sao chỉ có \(O(\log N)\) light edges trên đường đi
- HLD biến đường đi trên cây thành \(O(\log N)\) đoạn liên tục
- Truy vấn min/max/sum trên đường đi trong \(O(\log^2 N)\)
- Cách áp dụng HLD cho truy vấn subtree, LCA, và cập nhật cạnh
Bản chất vấn đề¶
Phát biểu¶
Cho cây \(N\) đỉnh (\(N \leq 10^5\)), mỗi đỉnh có một giá trị. Hỗ trợ hai loại truy vấn:
| Loại truy vấn | Mô tả |
|---|---|
UPDATE(u, val) |
Gán giá trị val cho đỉnh \(u\) |
QUERY(u, v) |
Tìm tổng / min / max trên đường đi từ \(u\) đến \(v\) |
Tại sao bài toán khó?¶
Với mỗi truy vấn QUERY(u, v), ta cần duyệt toàn bộ đường đi từ \(u\) lên LCA rồi xuống \(v\). Cách naïve mất \(O(N)\) mỗi truy vấn, \(Q\) truy vấn sẽ là \(O(N \cdot Q)\) — quá chậm với \(N, Q = 10^5\).
Đường đi trên cây không phải là một đoạn liên tục trong mảng, nên không thể dùng Segment Tree trực tiếp.
Giải pháp¶
Dùng Heavy-Light Decomposition (HLD) để biến đường đi trên cây thành \(O(\log N)\) đoạn liên tục trong mảng, rồi dùng Segment Tree trên mỗi đoạn.
Tư duy cốt lõi¶
Heavy Edge và Light Edge¶
Với mỗi đỉnh \(u\) (không phải lá), gọi \(sz[v]\) là kích thước cây con gốc \(v\).
- Heavy edge của \(u\): cạnh nối \(u\) với con \(v\) mà \(sz[v]\) lớn nhất (nếu nhiều con cùng kích thước, chọn bất kỳ).
- Light edge của \(u\): tất cả các cạnh còn lại từ \(u\) đến các con.
graph TD
A["1 (sz=10)"] -->|"heavy, sz=7"| B["3"]
A -->|"light, sz=4"| C["2"]
B --> D["6"]
B --> E["7"]
C --> F["4"]
C --> G["5"]
G --> H["8"]Cạnh \((1, 3)\) là heavy edge vì \(sz[3] = 7 > sz[2] = 4\).
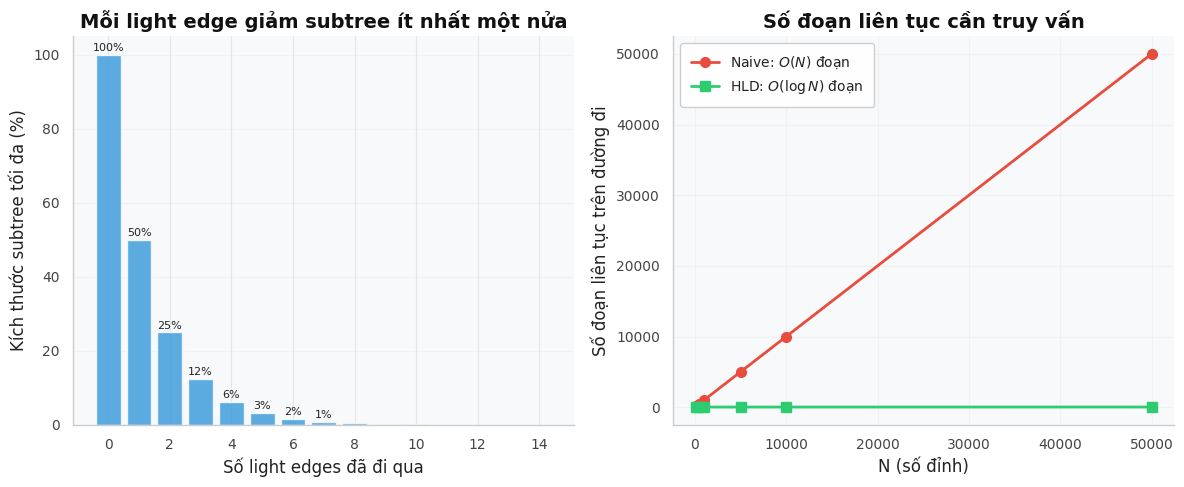
Tính chất cốt lõi: Light edges giảm một nửa kích thước¶
Định lý
Trên đường đi từ gốc đến bất kỳ lá, có tối đa \(\log N\) light edges.
Chứng minh: Khi đi qua một light edge từ \(u\) sang con \(v\), ta có \(sz[v] \leq sz[u]/2\) (vì \(v\) không phải heavy child). Vậy kích thước cây con giảm ít nhất một nửa. Sau tối đa \(\log N\) bước, kích thước giảm xuống 1.
Đây chính là "bí mật" khiến HLD hoạt động hiệu quả: mỗi lần nhảy qua light edge, cây con co lại ít nhất một nửa.
Chain Decomposition - Phân rã chuỗi¶
Mỗi heavy path (chuỗi các heavy edges liên tiếp) tạo thành một chain. Ta gán DFS order (thứ tự duyệt) sao cho mỗi chain là một đoạn liên tục trong mảng.
graph TD
subgraph "Cây gốc"
A1["1"] -->|"heavy"| A2["2"]
A1 -->|"light"| A3["3"]
A2 -->|"heavy"| A4["4"]
A2 -->|"light"| A5["5"]
A3 -->|"heavy"| A6["6"]
A4 -->|"heavy"| A7["7"]
end
subgraph "Chain 1: pos 1-4"
B1["pos=1"] --- B2["pos=2"] --- B3["pos=3"] --- B4["pos=4"]
end
subgraph "Chain 2: pos 5-6"
B5["pos=5"] --- B6["pos=6"]
end
subgraph "Chain 3: pos 7"
B7["pos=7"]
endMỗi chain ứng với một đoạn liên tục trong mảng, nên có thể dùng Segment Tree trên toàn bộ mảng.
Các biến cần lưu trữ¶
| Biến | Ý nghĩa |
|---|---|
| \(pos[u]\) | Vị trí của đỉnh \(u\) trong mảng (theo DFS order) |
| \(head[u]\) | Đỉnh đầu tiên trong chain chứa \(u\) |
| \(heavy[u]\) | Con nặng (heavy child) của \(u\), \(-1\) nếu là lá |
| \(parent[u]\) | Cha của \(u\) |
| \(depth[u]\) | Độ sâu của \(u\) |
| \(sz[u]\) | Kích thước cây con gốc \(u\) |
Bước 1: DFS tìm Heavy Child¶
DFS tính \(parent\), \(depth\), \(sz\), \(heavy\) cho mỗi đỉnh.
Bước 2: Decompose - Gán DFS Order¶
Thứ tự thăm đỉnh rất quan trọng: gốc, heavy child, heavy child của heavy child, rồi quay lại light children. Nhờ vậy, toàn bộ heavy path được gán liên tục trong mảng \(pos[]\).
Bước 3: Segment Tree trên mảng¶
Sau khi decompose, ta có mảng arr[] phẳng. Dùng Segment Tree để truy vấn / cập nhật trên mảng này.
Bước 4: Path Query - Truy vấn đường đi¶
Để truy vấn đường đi từ \(u\) đến \(v\):
- Miễn là \(head[u] \neq head[v]\), nhảy lên chain chứa đỉnh sâu hơn.
- Khi \(head[u] = head[v]\), truy vấn đoạn còn lại giữa \(u\) và \(v\).
Mỗi bước nhảy qua một light edge, tối đa \(O(\log N)\) bước.
Code đầy đủ (Full Solution)¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | |
Phân tích tính đúng đắn¶
Bước chạy chi tiết (Trace)¶
Cho cây sau với giá trị tại mỗi đỉnh:
graph TD
T1["1 (val=5)"] --> T2["2 (val=2)"]
T1 --> T3["3 (val=7)"]
T2 --> T4["4 (val=2)"]
T2 --> T5["5 (val=1)"]
T3 --> T6["6 (val=3)"]Trace bước 1: DFS tính \(sz\) và \(heavy\)¶
DFS từ đỉnh 1, tính toán đệ quy từ lá lên:
| \(u\) | \(sz[u]\) | \(heavy[u]\) | \(depth[u]\) | \(parent[u]\) |
|---|---|---|---|---|
| 4 | 1 | -1 | 2 | 2 |
| 5 | 1 | -1 | 2 | 2 |
| 2 | 3 | 4 | 1 | 1 |
| 6 | 1 | -1 | 2 | 3 |
| 3 | 2 | 6 | 1 | 1 |
| 1 | 6 | 2 | 0 | -1 |
Đỉnh 2 được chọn làm heavy child của 1 vì \(sz[2] = 3 > sz[3] = 2\).
Trace bước 2: Decompose - Gán DFS Order¶
Thứ tự gán \(pos\): ưu tiên heavy child trước.
| Bước | Gọi | \(head\) | \(pos\) | \(arr\) |
|---|---|---|---|---|
| 1 | decompose(1, 1) | 1 | 0 | 5 |
| 2 | decompose(2, 1) | 1 | 1 | 2 |
| 3 | decompose(4, 1) | 1 | 2 | 2 |
| 4 | decompose(5, 5) | 5 | 3 | 1 |
| 5 | decompose(3, 3) | 3 | 4 | 7 |
| 6 | decompose(6, 3) | 3 | 5 | 3 |
Kết quả:
| \(u\) | \(head[u]\) | \(pos[u]\) | Chain |
|---|---|---|---|
| 1 | 1 | 0 | 1-2-4 |
| 2 | 1 | 1 | 1-2-4 |
| 4 | 1 | 2 | 1-2-4 |
| 5 | 5 | 3 | 5 |
| 3 | 3 | 4 | 3-6 |
| 6 | 3 | 5 | 3-6 |
Mảng \(arr[] = [5, 2, 2, 1, 7, 3]\).
Trace bước 3: Truy vấn QUERY(4, 6)¶
Tìm tổng trên đường đi \(4 \to 2 \to 1 \to 3 \to 6\). Kỳ vọng: \(2 + 2 + 5 + 7 + 3 = 19\).
Vòng lặp 1: \(head[4] = 1\), \(head[6] = 3\), khác nhau.
- \(depth[head[4]] = 0 < depth[head[6]] = 1\), nên nhảy chain của đỉnh 6.
- \(query(pos[head[6]], pos[6]) = query(4, 5) = arr[4] + arr[5] = 7 + 3 = 10\).
- \(v = parent[head[6]] = parent[3] = 1\).
- \(res = 10\).
Vòng lặp 2: \(head[4] = 1\), \(head[1] = 1\), giống nhau.
- \(depth[4] = 2 > depth[1] = 0\), swap: \(u = 1, v = 4\).
- \(query(pos[1], pos[4]) = query(0, 2) = arr[0] + arr[1] + arr[2] = 5 + 2 + 2 = 9\).
- \(res = 10 + 9 = 19\).
Kết quả: \(19 = (5 + 2 + 2) + (7 + 3) = 9 + 10\). Đúng!
Tại sao HLD luôn đúng?¶
Tính chất 1: Mỗi heavy path là đoạn liên tục.
Hàm decompose luôn thăm heavy child ngay sau đỉnh hiện tại (cùng giá trị \(head\)). Các light children được thăm sau, tạo chain mới. Do đó toàn bộ một heavy path nhận \(pos\) liên tiếp.
Tính chất 2: Đường đi bất kỳ gồm \(O(\log N)\) đoạn liên tục.
Đường đi từ \(u\) đến \(v\) đi qua LCA. Trên mỗi nửa đường (từ \(u\) lên LCA, từ \(v\) lên LCA), mỗi lần nhảy qua light edge, kích thước cây con giảm ít nhất một nửa. Số light edges tối đa là \(\log N\), nên số đoạn liên tục tối đa là \(2 \log N = O(\log N)\).
Tính chất 3: Subtree là đoạn liên tục.
Trong DFS, toàn bộ cây con của \(u\) được thăm liên tục trước khi quay lại. Do đó:
Đánh giá độ phức tạp¶
Độ phức tạp thời gian¶
| Loại truy vấn | Độ phức tạp | Giải thích |
|---|---|---|
| Path query \((u, v)\) | \(O(\log^2 N)\) | \(O(\log N)\) đoạn \(\times\) \(O(\log N)\) mỗi đoạn trên SegTree |
| Subtree query \((u)\) | \(O(\log N)\) | 1 lần truy vấn SegTree trên đoạn \([pos[u], pos[u] + sz[u] - 1]\) |
| Update node \((u)\) | \(O(\log N)\) | 1 lần cập nhật SegTree |
| LCA \((u, v)\) | \(O(\log N)\) | Nhảy chain, không cần SegTree |
Tổng cho \(Q\) truy vấn: \(O(Q \log^2 N)\).
Độ phức tạp bộ nhớ¶
- Mảng adjacency: \(O(N)\).
- Các mảng \(parent\), \(depth\), \(sz\), \(heavy\), \(head\), \(pos\): \(O(N)\).
- Segment Tree: \(O(N)\).
- Tổng: \(O(N)\).
So sánh với các phương pháp khác¶
| Phương pháp | Path query | Subtree query | Update node | Bộ nhớ |
|---|---|---|---|---|
| HLD + SegTree | \(O(\log^2 N)\) | \(O(\log N)\) | \(O(\log N)\) | \(O(N)\) |
| Euler Tour + BIT | Không hỗ trợ | \(O(\log N)\) | \(O(\log N)\) | \(O(N)\) |
| Binary Lifting | \(O(\log N)\) tìm LCA | Không hỗ trợ | Không hỗ trợ | \(O(N \log N)\) |
| Centroid Decomposition | \(O(\log^2 N)\) | \(O(\log N)\) | \(O(\log^2 N)\) | \(O(N \log N)\) |
HLD là lựa chọn tốt nhất khi cần cả path query lẫn subtree query với bộ nhớ \(O(N)\).
Ứng dụng mở rộng¶
Tìm LCA bằng HLD¶
Trên đường đi từ \(u\) lên \(v\), đỉnh cuối cùng trước khi \(head[u] = head[v]\) chính là LCA.
Độ phức tạp: \(O(\log N)\), nhanh hơn Binary Lifting về hằng số.
Cập nhật cạnh (Edge Queries)¶
Khi cần truy vấn giá trị trên cạnh thay vì đỉnh: gán giá trị của cạnh \((parent[u], u)\) vào đỉnh \(u\) (đỉnh sâu hơn).
Khi truy vấn đường đi \(u \to v\), cần loại trừ đỉnh LCA vì cạnh \((parent[\text{LCA}], \text{LCA})\) không thuộc đường đi.
Cập nhật đường đi (Path Update)¶
Kết hợp HLD với Lazy Propagation Segment Tree để hỗ trợ UPDATE_PATH(u, v, val): thêm val vào tất cả đỉnh trên đường đi \(u \to v\).
Min/Max trên đường đi¶
Thay Segment Tree sum bằng Segment Tree min/max. Chỉ cần đổi phép toán trong Segment Tree.
Lưu ý và cạm bẫy¶
Thứ tự gọi DFS và Decompose¶
Phải gọi dfs(1, -1) trước decompose(1, 1) trước st.build(). Gọi sai thứ tự sẽ khiến \(sz[]\), \(heavy[]\) chưa được tính.
Nhầm \(pos[]\) và \(depth[]\)¶
- \(pos[u]\): vị trí trong mảng, dùng cho Segment Tree.
- \(depth[u]\): độ sâu trong cây, dùng cho so sánh chain.
Dùng nhầm sẽ sai kết quả mà không báo lỗi.
Quên cập nhật Segment Tree¶
Sau khi HLD, mọi cập nhật phải đi qua Segment Tree. Không được gán trực tiếp vào mảng cũ.
Stack overflow với cây sâu¶
Cây sâu có thể gây tràn đệ quy. C++ cần tăng stack size hoặc dùng iterative DFS. Python cần gọi sys.setrecursionlimit(300000).
Bài tập luyện tập¶
| Mã bài | Tên bài tập | Độ khó | Kiểu bài tập (Bản chất) | Bài học lý thuyết |
|---|---|---|---|---|
hld-path-sum |
Tổng Trên Đường Đi | ⭐⭐⭐ | Tổng trọng số trên đường đi | HLD |
hld-path-max |
Max Trên Đường Đi | ⭐⭐⭐ | Giá trị lớn nhất trên đường đi | HLD |
hld-path-easy |
Đường Đi Dễ | ⭐ | Truy vấn đường đi cơ bản | HLD |
hld-subtree |
Truy Vấn Subtree | ⭐⭐ | Truy vấn trên subtree | HLD |
hld-edge-up |
Cập Nhật Cạnh | ⭐⭐⭐⭐ | Cập nhật trọng số cạnh + truy vấn đường đi | HLD |
hld-path-add |
Cộng Trên Đường Đi | ⭐⭐⭐ | Cộng giá trị trên đường đi | HLD |
hld-lca |
LCA Với HLD | ⭐⭐⭐ | Tìm LCA bằng HLD | HLD |
hld-all-path |
Toàn Bộ Truy Vấn Đường Đi | ⭐⭐⭐⭐ | Nhiều loại truy vấn trên đường đi | HLD |
hld-heavy-query |
Truy Vấn Heavy Path | ⭐⭐⭐⭐ | Truy vấn nâng cao trên heavy path | HLD |
Tóm tắt¶
| Khái niệm | Mô tả |
|---|---|
| Heavy edge | Cạnh nối đỉnh với con có cây con lớn nhất |
| Light edge | Các cạnh còn lại, tối đa \(\log N\) trên đường đi |
| Chain | Chuỗi heavy edges liên tiếp, ứng với đoạn liên tục |
| \(pos[u]\) | Vị trí đỉnh \(u\) trong mảng DFS order |
| \(head[u]\) | Đỉnh đầu chain chứa \(u\) |
| Path query | \(O(\log^2 N)\) - nhảy chain + Segment Tree |
| Subtree query | \(O(\log N)\) - 1 lần Segment Tree |
| LCA | \(O(\log N)\) - nhảy chain |
Điểm mấu chốt: HLD biến đường đi trên cây thành \(O(\log N)\) đoạn liên tục. Mỗi đoạn liên tục truy vấn Segment Tree mất \(O(\log N)\). Tổng mỗi truy vấn đường đi: \(O(\log^2 N)\).
Lời khuyên: Hãy hiểu rõ DFS order trên cây trước khi học HLD. HLD chỉ là "DFS order thông minh" — ưu tiên thăm heavy child trước!
Bài tiếp theo: Bài 47: DP trên cây