Bài 16: Hash Table (Bảng Băm)¶
Tác giả: FPTOJ Team
Nội dung tham khảo từ: VNOI Wiki - Bảng băm
Bản chất vấn đề¶
Bài toán cơ bản: Cho một tập hợp \(N\) phần tử, xây dựng cấu trúc dữ liệu hỗ trợ ba thao tác — chèn, tìm kiếm, xóa — với tốc độ nhanh nhất có thể.
Một cách tiếp cận trực tiếp là sử dụng mảng hoặc danh sách liên kết, duyệt tuần tự để tìm phần tử. Độ phức tạp mỗi thao tác là \(O(N)\). Khi \(N\) lớn và số lượng truy vấn nhiều, cách này trở nên quá chậm.
Ví dụ, với 100.000 từ trong từ điển và 100.000 truy vấn, duyệt tuần tự tốn \(O(N^2) = O(10^{10})\) phép tính — không khả thi.
Câu hỏi cốt lõi: Làm sao truy cập trực tiếp đến phần tử mong muốn mà không cần duyệt qua tất cả?
Giải pháp là Hash Table — một cấu trúc dữ liệu cho phép trung bình \(O(1)\) cho mỗi thao tác chèn, tìm kiếm, xóa. Ý tưởng chính là sử dụng một hàm băm \(h(key)\) để chuyển đổi key thành chỉ số trong mảng, từ đó truy cập trực tiếp đến vị trí lưu trữ.
Tư duy cốt lõi¶
Hàm băm (Hash Function)¶
Hàm băm \(h\) nhận vào một key (số nguyên, xâu, hoặc bất kỳ kiểu dữ liệu nào) và trả về một chỉ số trong mảng \(table[0..M-1]\):
Một hàm băm tốt cần thỏa mãn ba tính chất:
- Nhanh: Tính được trong \(O(1)\) hoặc \(O(|key|)\)
- Phân phối đều: Các key khác nhau nên rơi vào các vị trí khác nhau, tránh tập trung vào một vài ô
- Xác định: Cùng key luôn cho cùng giá trị hash
Hệ số 31 là một số nguyên tố nhỏ, giúp phân phối đều. Giá trị tableSize nên chọn là số nguyên tố để giảm xung đột.
Xử lý xung đột (Collision)¶
Hàm băm ánh xạ không gian key vô hạn vào mảng kích thước hữu hạn \(M\), nên xung đột là không thể tránh khỏi — hai key khác nhau có thể cùng hash về một vị trí.
Có hai phương pháp chính để xử lý xung đột.
Phương pháp 1: Chaining (Danh sách liên kết)
Mỗi ô trong bảng băm là một danh sách liên kết. Khi nhiều key cùng hash về một ô, chúng được lưu trong cùng danh sách đó.
graph LR
subgraph "Bảng băm (M = 5)"
A0["[0]"] --> N0["∅"]
A1["[1]"] --> B1["cat: 3"] --> B2["dog: 5"] --> N1["∅"]
A2["[2]"] --> C1["bird: 2"] --> N2["∅"]
A3["[3]"] --> N3["∅"]
A4["[4]"] --> D1["fish: 1"] --> N4["∅"]
endTrong ví dụ trên, "cat" và "dog" cùng có hash bằng 1, nên chúng nằm trong cùng một danh sách tại ô [1].
Phương pháp 2: Open Addressing (Địa chỉ mở)
Khi xung đột, ta tìm một ô trống khác trong bảng theo một quy tắc xác định:
| Chiến lược | Quy tắc tìm ô | Bước nhảy |
|---|---|---|
| Linear Probing | Thử \(h(k)+1, h(k)+2, h(k)+3, \ldots\) | \(1, 2, 3, \ldots\) |
| Quadratic Probing | Thử \(h(k)+1^2, h(k)+2^2, h(k)+3^2, \ldots\) | \(1, 4, 9, \ldots\) |
| Double Hashing | Dùng hàm băm thứ 2 \(h_2(k)\) làm bước nhảy | \(h_2(k), 2h_2(k), \ldots\) |
So sánh hai phương pháp¶
| Tiêu chí | Chaining | Open Addressing |
|---|---|---|
| Dễ cài đặt | Dễ hơn | Khó hơn |
| Bộ nhớ | Nhiều hơn (con trỏ) | Ít hơn |
| Khi load factor cao | Vẫn hoạt động tốt | Rất chậm |
| Cache performance | Kém hơn (nhảy theo con trỏ) | Tốt hơn (truy cập tuần tự) |
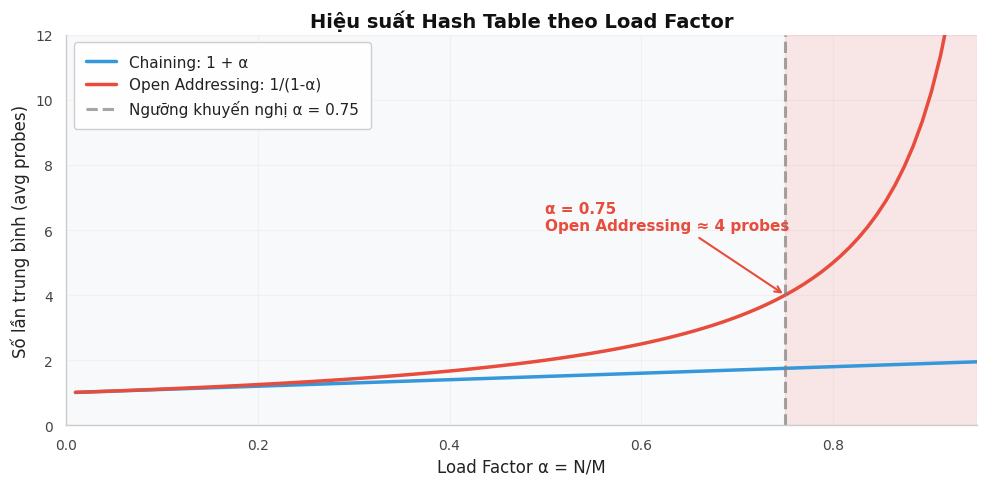
Load Factor và Rehashing¶
Load factor \(\alpha\) là tỷ lệ giữa số phần tử và kích thước bảng:
Khi \(\alpha\) vượt quá ngưỡng (thường là 0.75), hiệu suất giảm do xung đột tăng. Lúc này cần rehashing: tạo bảng mới lớn gấp đôi, rồi đưa tất cả phần tử sang.
Thư viện chuẩn¶
Ứng dụng trong thi đấu¶
Hash table là công cụ cực kỳ phổ biến trong lập trình thi đấu. Bảng sau tổng hợp các mẫu bài toán thường gặp:
| Bài toán | Cấu trúc dùng | Ví dụ |
|---|---|---|
| Đếm tần suất xuất hiện | unordered_map<value, count> |
Đếm số lần xuất hiện của mỗi phần tử |
| Kiểm tra trùng lặp | unordered_set |
Mảng có phần tử giống nhau không? |
| Nhóm phần tử theo key | unordered_map<key, vector> |
Group Anagrams |
| Two Sum | unordered_map<value, index> |
Tìm 2 số có tổng bằng \(X\) |
| Đếm ký tự trong xâu | unordered_map<char, int> |
Kiểm tra xâu đối xứng |
Ví dụ: Đếm tần suất
Ví dụ: Two Sum — Tìm 2 số có tổng bằng \(X\)
Ý tưởng: Duyệt mảng, với mỗi phần tử \(a[i]\), kiểm tra \(X - a[i]\) đã xuất hiện chưa bằng hash table.
Ví dụ: Group Anagrams — Nhóm từ đảo chữ
Ý tưởng: Sắp xếp ký tự mỗi từ, từ đã sắp xếp chính là key. Các từ cùng key là đảo chữ của nhau.
Ví dụ: Kiểm tra phần tử trùng lặp
Cài đặt thủ công (Chaining)¶
Để hiểu sâu nguyên lý, dưới đây là cài đặt hash table đơn giản với phương pháp chaining.
Phân tích tính đúng đắn¶
Tại sao hash table hoạt động đúng?¶
Tính đúng đắn của hash table dựa trên hai tiền đề:
Tiền đề 1: Hàm băm xác định. Với cùng một key, hàm băm luôn trả về cùng một chỉ số. Điều này đảm bảo khi ta chèn một phần tử với key \(k\) vào vị trí \(h(k)\), sau đó tìm kiếm lại với key \(k\), ta luôn quay về đúng vị trí đó.
Tiền đề 2: Xung đột được giải quyết triệt để. Dù nhiều key có thể hash về cùng một vị trí, phương pháp chaining hoặc open addressing đảm bảo tất cả các key đều được lưu trữ và có thể tìm thấy.
Chứng minh tính đúng đắn của Chaining¶
Giả sử ta chèn \(N\) key vào bảng kích thước \(M\) với chaining.
-
Chèn key \(k\): Tính \(idx = h(k)\), duyệt danh sách tại \(table[idx]\). Nếu \(k\) đã tồn tại, cập nhật giá trị. Nếu chưa, thêm vào cuối danh sách. Thao tác này đúng vì mọi key có hash bằng \(idx\) đều nằm trong danh sách tại \(table[idx]\).
-
Tìm kiếm key \(k\): Tính \(idx = h(k)\), duyệt danh sách tại \(table[idx]\). Nếu tìm thấy \(k\), trả về giá trị. Nếu duyệt hết mà không thấy, key không tồn tại. Điều này đúng vì nếu \(k\) đã được chèn, nó phải nằm trong danh sách tại \(h(k)\).
-
Xóa key \(k\): Tương tự tìm kiếm, nhưng thay vì trả về, ta xóa node khỏi danh sách.
Chứng minh tính đúng đắn của Open Addressing¶
Với linear probing, giả sử ta chèn key \(k\) vào vị trí \(h(k)\) hoặc vị trí trống đầu tiên sau \(h(k)\).
Khi tìm kiếm key \(k\), ta bắt đầu từ \(h(k)\) và duyệt tuyến tính cho đến khi:
- Tìm thấy \(k\) — trả về giá trị
- Gặp ô trống — \(k\) không tồn tại
- Duyệt hết bảng — \(k\) không tồn tại
Điểm mấu chốt: Nếu \(k\) đã được chèn, ta chắc chắn tìm thấy nó vì ta đi theo đúng chuỗi probing mà nó đã đi qua khi chèn. Nếu gặp ô trống trước khi tìm thấy \(k\), điều đó có nghĩa \(k\) chưa bao giờ được chèn (vì nếu nó được chèn, nó sẽ nằm tại hoặc trước vị trí trống đó).
Anti-Hash Attack¶
Một điểm yếu của hash table là kẻ tấn công có thể cố tình tạo ra nhiều key có cùng hash, đẩy bảng vào worst case \(O(N)\) cho mỗi thao tác. Đây gọi là anti-hash attack.
Cách phòng chống:
- Sử dụng hàm băm ngẫu nhiên hóa (randomized hash)
- Dùng hai hàm băm độc lập (double hashing)
- Trong thi đấu, hiếm khi bị anti-hash attack vì dữ liệu đầu vào không được tạo bởi người dùng
Đánh giá độ phức tạp¶
Trường hợp trung bình (Average Case)¶
Giả sử hàm băm phân phối đều và load factor \(\alpha = N/M\).
| Thao tác | Chaining | Open Addressing |
|---|---|---|
| Chèn | \(O(1)\) | \(O(1)\) |
| Tìm kiếm | \(O(1 + \alpha)\) | \(\displaystyle O\!\left(\frac{1}{1-\alpha}\right)\) |
| Xóa | \(O(1 + \alpha)\) | \(\displaystyle O\!\left(\frac{1}{1-\alpha}\right)\) |
Khi \(\alpha\) nhỏ (ví dụ \(\alpha \leq 0.75\)), tất cả các thao tác đều gần \(O(1)\).
Trường hợp tệ nhất (Worst Case)¶
Khi tất cả \(N\) key đều hash về cùng một vị trí:
| Thao tác | Chaining | Open Addressing |
|---|---|---|
| Chèn | \(O(N)\) | \(O(N)\) |
| Tìm kiếm | \(O(N)\) | \(O(N)\) |
| Xóa | \(O(N)\) | \(O(N)\) |
Worst case xảy ra khi hàm băm kém hoặc bị anti-hash attack. Trong thực tế, với hàm băm tốt và load factor được kiểm soát, worst case rất hiếm.
So sánh với các cấu trúc khác¶
| Cấu trúc | Tìm kiếm trung bình | Tìm kiếm tệ nhất | Có thứ tự |
|---|---|---|---|
| Hash Table | \(O(1)\) | \(O(N)\) | Không |
Cây đỏ-đen (map) |
\(O(\log N)\) | \(O(\log N)\) | Có |
| Mảng + Binary Search | \(O(\log N)\) | \(O(\log N)\) | Có |
| Danh sách liên kết | \(O(N)\) | \(O(N)\) | Không |
Lựa chọn cấu trúc phụ thuộc vào yêu cầu:
- Cần tìm kiếm nhanh nhất, không cần thứ tự — Hash Table
- Cần duy trì thứ tự — Cây đỏ-đen
- Dữ liệu tĩnh (không chèn/xóa) — Mảng + Binary Search
Tóm tắt¶
- Trung bình: \(O(1)\) cho mọi thao tác — đây là ưu điểm lớn nhất của hash table
- Worst case: \(O(N)\) — xảy ra khi tất cả key cùng hash hoặc bị anti-hash attack
- Bộ nhớ: \(O(N)\) — cần thêm không gian cho bảng băm và các cấu trúc xử lý xung đột
- Load factor \(\alpha < 0.75\): Ngưỡng khuyến nghị để đảm bảo hiệu suất tốt
Bài tập luyện tập¶
| Bài | FPTOJ | Độ khó | Chủ đề |
|---|---|---|---|
strb-anagram |
Hoán vị xâu | ⭐⭐ | Đếm tần suất Map |
strh-hash |
Tính hash cơ bản | ⭐ | Hash xâu |
strh-dist |
Đếm xâu con phân biệt | ⭐⭐ | Hash + Set |
strh-find |
Tìm xâu con bằng Hash | ⭐⭐ | Rabin-Karp |
strh-palind |
Palindrome với Hash | ⭐⭐⭐ | Hash + truy vấn |
trie-insert-search |
Tập Từ Vựng Cây Tiền Tố | ⭐ | Trie |
Bài viết liên quan¶
Tài liệu tham khảo¶
- VNOI Wiki - Bảng băm
- CP-Algorithms - Hash Table
- GeeksforGeeks - Hashing Data Structure
- Codeforces - Hash Tables
Bài tiếp theo: Trie